- Published on
⭐Why Your First Token Is Always Late
- Authors

- Name
- Anirudh Sathiya Narayanan
If you've ever sat in a systems software engineer interview, you've probably been asked "Walk me through what happens when you type google.com and hit enter."
You answer: DNS resolution, TCP handshake, HTTP request, load balancer, index lookup, ranked results. You could probably draw it on a whiteboard in under a minute with a coffee in your other hand.
Now try this interview question: walk me through what happens between you asking ChatGPT "explain quantum computing like I'm five" and it responding with "great question!"
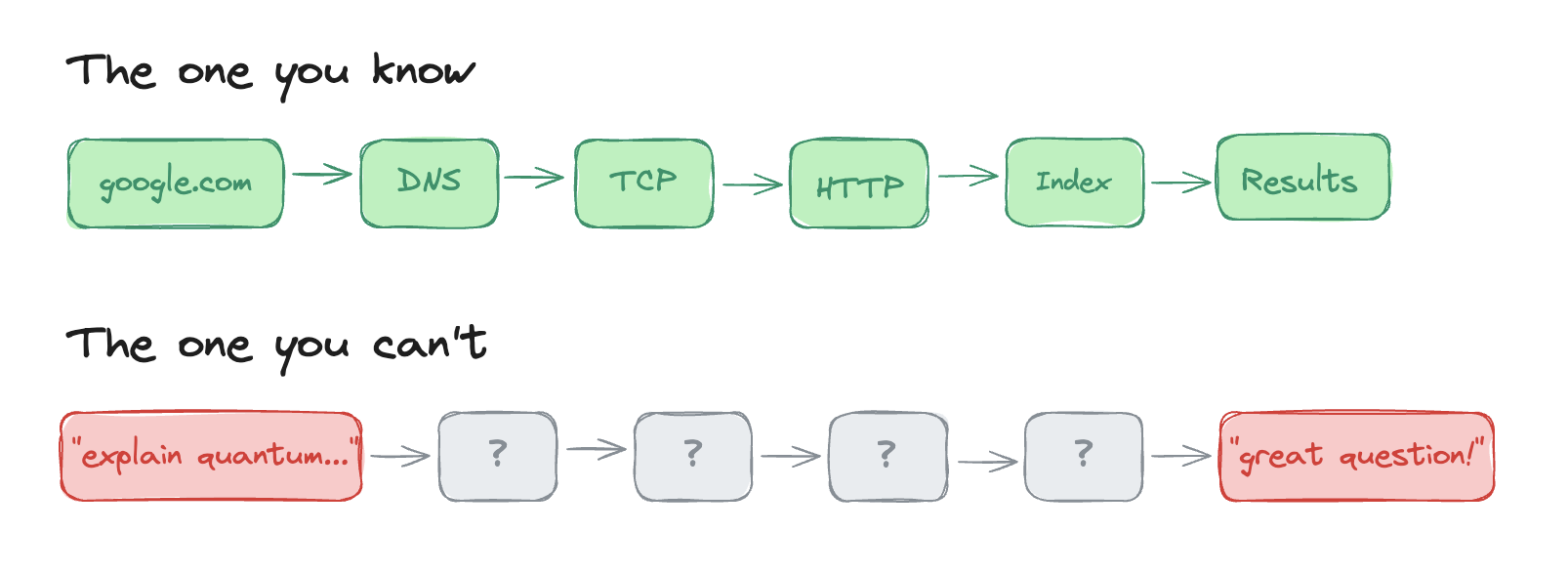
Most engineers jump straight to model weights and matrix multiplications. Fair enough, but there's a lot that's unspoken about the inference pipeline. Why do output tokens cost 4-8x more than input tokens? Why does doubling your context window do worse than double the damage to your bill? Why is the first token always the slowest?
I built a full inference server, BPE tokenizer and transformer from scratch in C++ to answer these questions. This blog is part 2 of a 3-part series. Part 1 covers tokenization if you want the buildup, but you don't need it. By now, your prompt is a list of token IDs. Let's talk about what happens next.
The Transformer Model at a Glance
Before the fun stuff, here's the full forward pass pipeline for reference. I have illustrated each stage with a summary and an example.
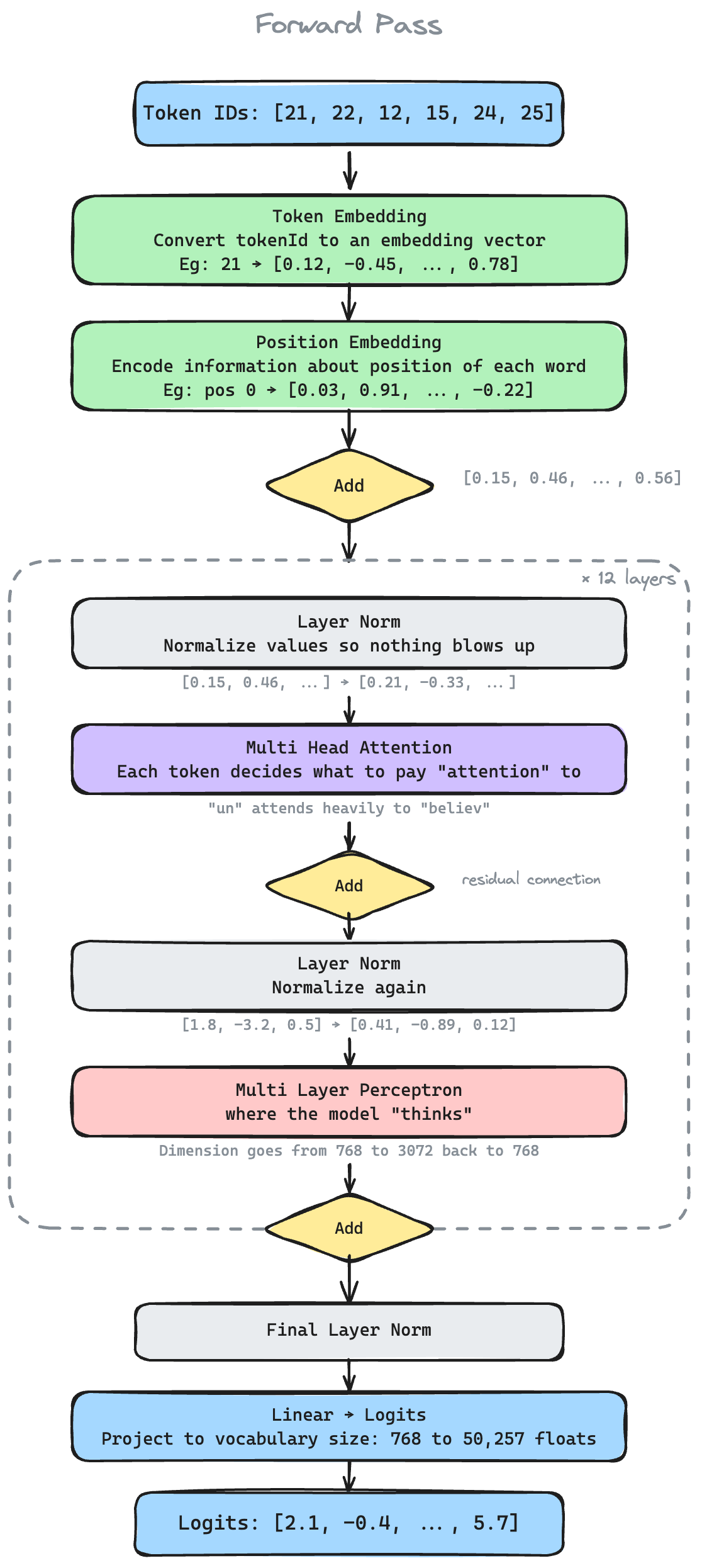
If this is new to you, 3Blue1Brown and Jay Alammar's walkthroughs are the best place to start. This blog assumes you get the gist and focuses on the inference aspect of LLMs.
Why is the first token so slow to generate? But not the rest?
Have you noticed that when you prompt ChatGPT, there's a short pause and suddenly the tokens start streaming? The reason why takes us to the heart of inference.
Prefill Phase

Context changes meaning. "Bananas" in "I love bananas" means something very different from what it means in "He went bananas!". Before predicting the next token, the model needs to resolve this. So every token attends to every other, weighing how much each one matters. That's where the term "attention" comes from.
Attention gets computed using key and value vectors. Each token gets projected into three vectors: a Query (what am I looking for?), a Key (what do I contain?), and a Value (what do I output?).
This is the famous equation from the paper: "Attention is all you need".
, = dimension of key vector
This is since is a matrix.
Hence, prefill is the more compute intensive phase.
That's why you need to wait so long for the first token!
KV Cache
During prefill, every token produces a Key vector and a Value vector at every layer. Rather than throwing these away, the model stores them in a structure called the KV Cache. During decode, each new token only needs to compute its own Query vector, then look up the cached Keys and Values to compute attention. That's why Q isn't cached. Only the current token's query matters, but every previous token's Key and Value are still needed.
The KV Cache grows by one row per token per layer. This is the structure that dominates GPU memory during inference, and the reason the rest of this post keeps coming back to it.
Decode Phase
By the end of prefill, every token's hidden state reflects the full context. The model uses the representation at the last position (i.e. "bananas") to predict the next token, and the decode phase begins. This stage generates one new token at a time.
To predict the next token, we compute using the already cached Key and Value vectors. This means each decode step is instead of .
You'd think that would make it N times faster than the prefill phase. But the catch is that for every single token, the GPU has to read through the entire KV Cache from High Bandwidth Memory (HBM) into compute units. For frontier models, this could reach hundreds of gigabytes per request! This makes decode memory bandwidth bound.
This is also why API providers charge 4-8x more for output tokens (decode) as compared to input tokens (prefill).
Why does context length murder your bills?
When you paste a long document into ChatGPT and ask it to summarize, the model runs attention across every pair of tokens. So double the document, quadruple the compute. But compute isn't the only cost that explodes. A 1M context window means the KV Cache has to store up to one million token positions.
Rough napkin math for Llama 3.1 model, which has 128 layers, hidden dimension of 16384, max context of 128K tokens, bf16 (2 byte value)
KV Cache for:
- one token: 2 bytes * 16384 hidden dimensions * 2 (for Key + Value vectors) = 64KB
- all 128 layers = 64 KB * 128 ~=8MB (assuming MHA, i.e. one KV head per query head)
- max context of 128K tokens = 8 MB * 128000 =~ 1 TB per request
Holy sheep.
Let's look at the stock price of one of the largest High Bandwidth Memory producers.
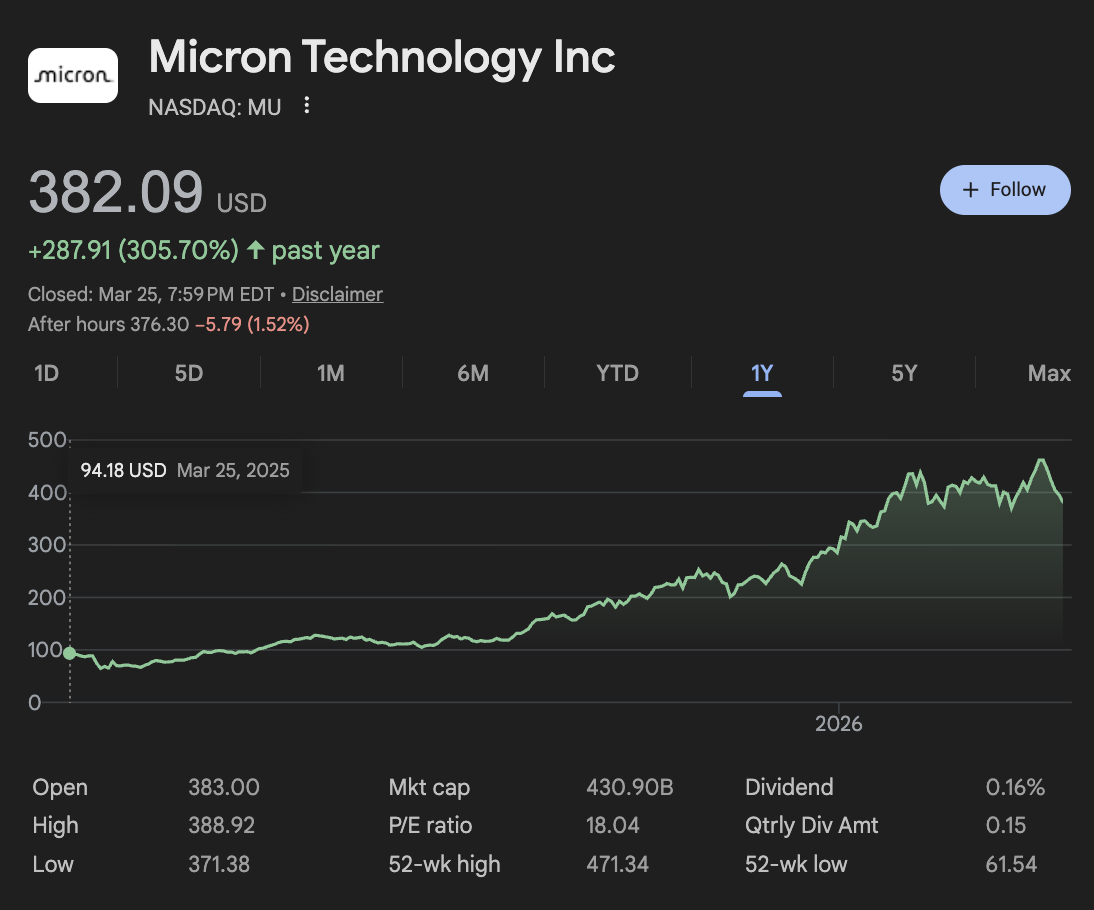
4X over the last year? Checks out :')
Group Query Attention
That 1TB KV Cache size number assumes every attention head gets its own Key and Value vectors. In practice, Llama 3.1 uses Grouped-Query Attention; instead of 128 separate KV heads, groups of 16 query heads share the same KV pair. That brings our 1TB down to ~64GB per request. Still enormous, but now it actually fits on hardware that exists.
Okay how do we scale from one user to a million?
Continuous Batching
Microsoft's 2022 Orca (Yu et al.) paper introduced this optimization to better streamline inference. Production servers batch multiple users' requests into a single forward pass. This is done to maximize GPU utilization. For example, the following requests can be batched together as one request.
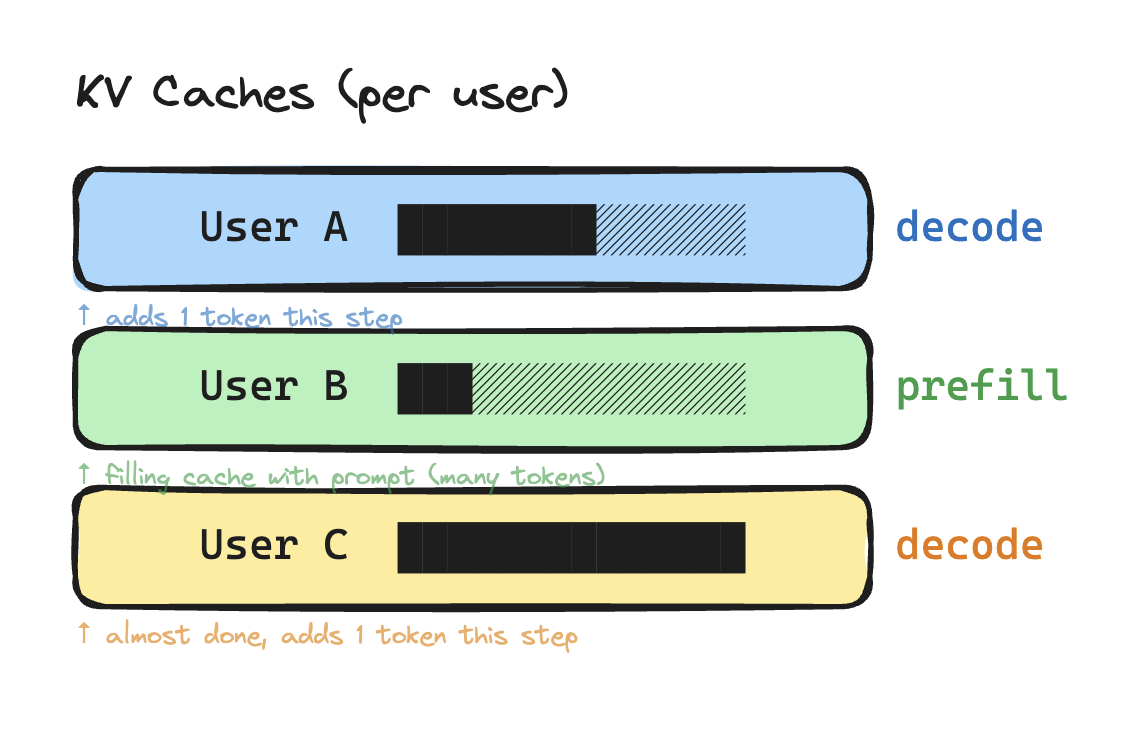
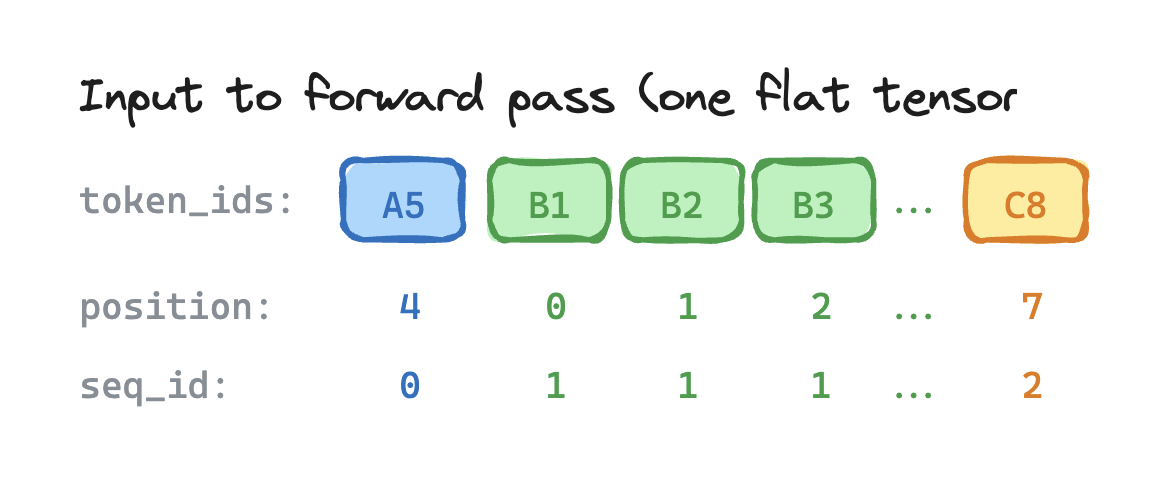
After tokenization, different users' tokens are concatenated into one flat vector. This is combined with position IDs to tell the system which tokens belong together. In the example below, each color denotes a different request.
Since the transformer will try to "attend" to all these tokens as if they came from one request, we need to isolate them with an attention mask. This is done as visualized.
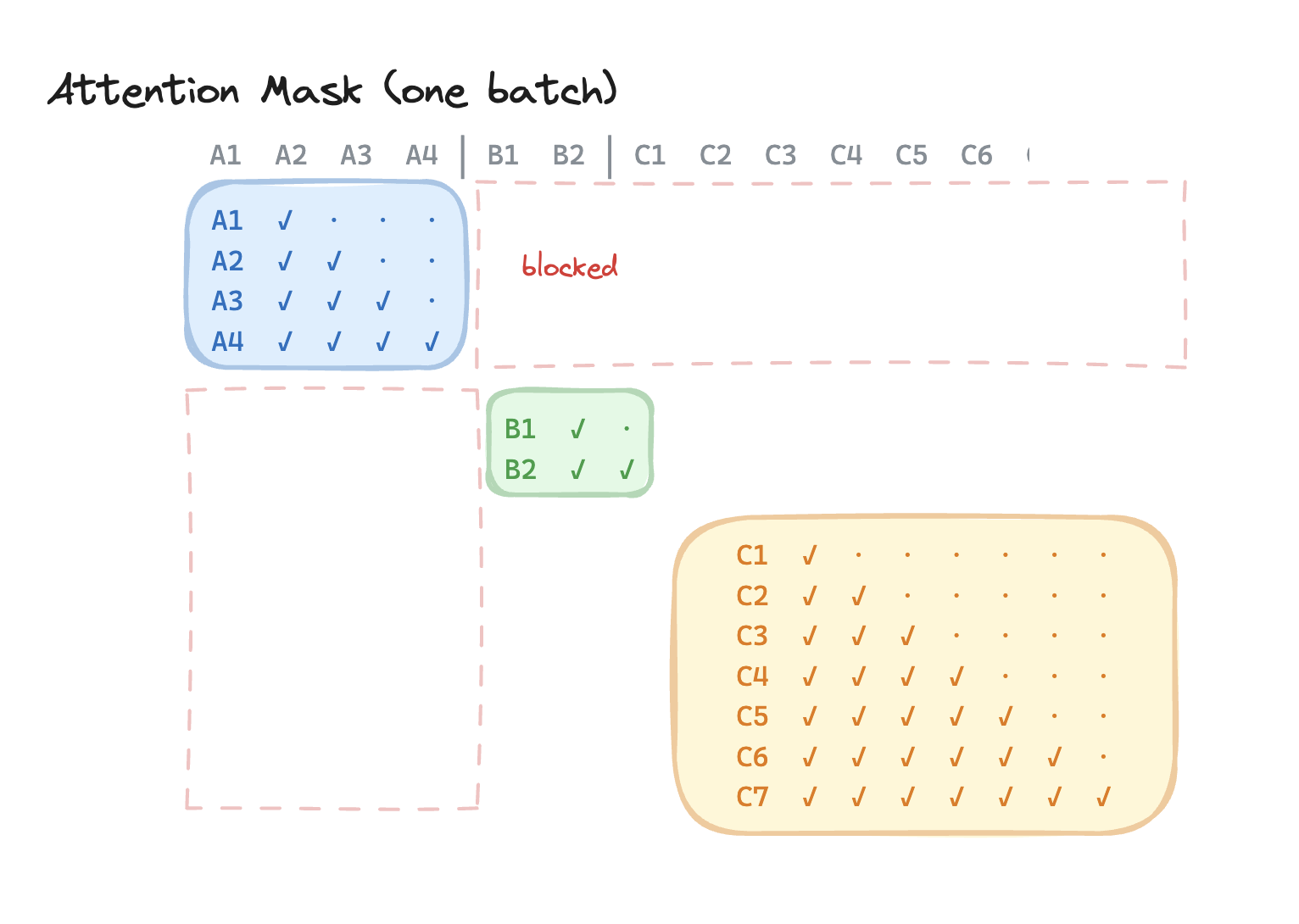
For you astute readers out there, you might notice that we're still mixing decode requests with slower prefill requests. Here, User A's request might take longer to come because of batching it with User B's. That brings us to our next optimization.
Chunked Prefill
Chunked prefill breaks prefill requests into multiple chunks. Decode requests don't need to be chunked as they consist of only one token per step.
Let's visually compare how the input to our model looks like with and without chunked prefill.
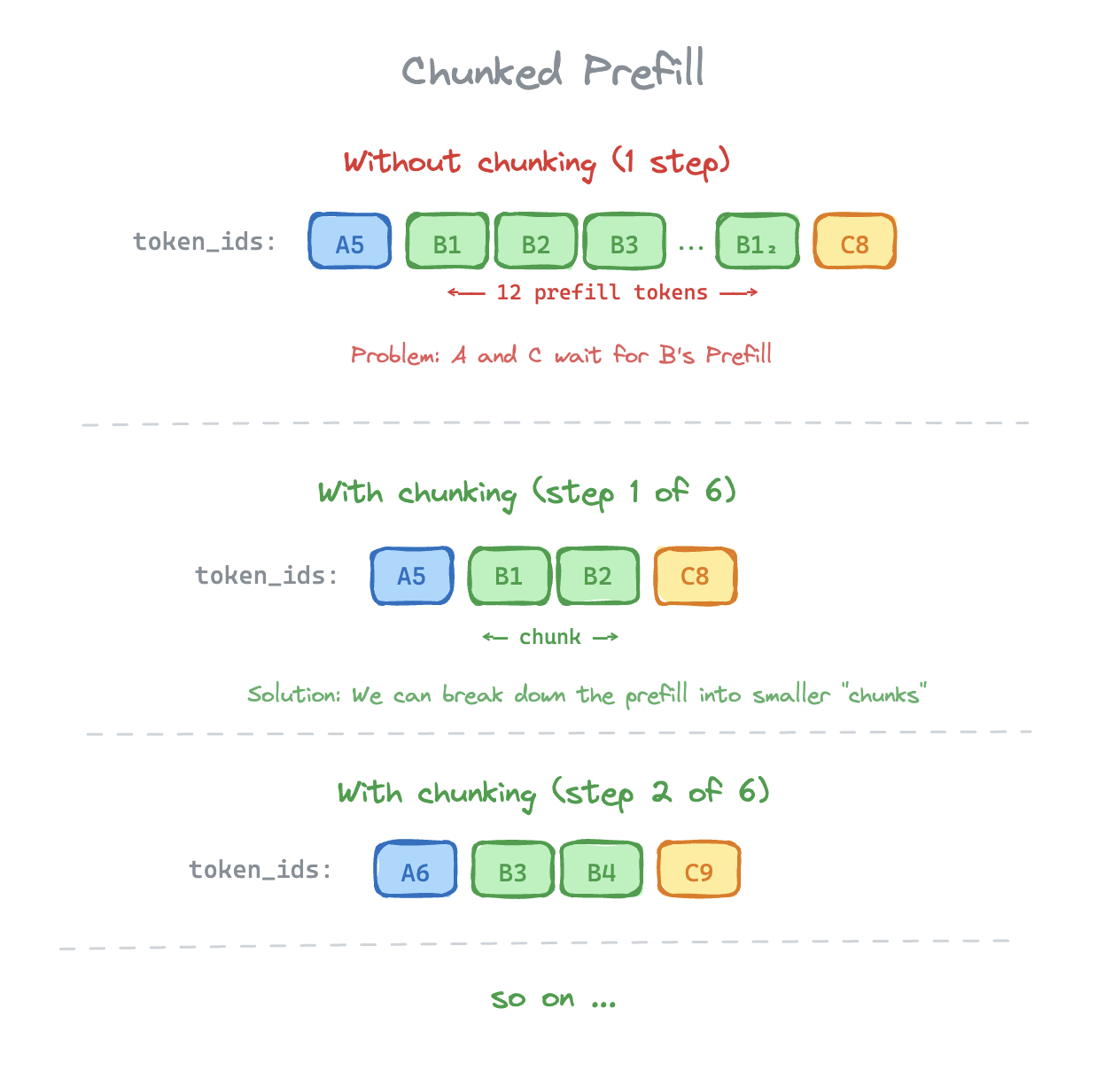
This further improves GPU utilization and improves decode throughput when combined with continuous batching. For example, chunked prefill is the reason why a 200 page document summarization prompt doesn't bottleneck the inference service.
Speculative decoding
The problem is that decoding is sequential. Each token depends on the last and takes one forward pass to execute. That's expensive.
Speculative decoding cheats by using a small, fast "draft" model to guess the next 'n' tokens.
The big model verifies all "n" tokens in one forward pass. Verification works like prefill. The big model takes the 'n' tokens as input, computes the logits at each position and checks whether the draft model's picks match. Everything up to the first mismatch gets accepted.
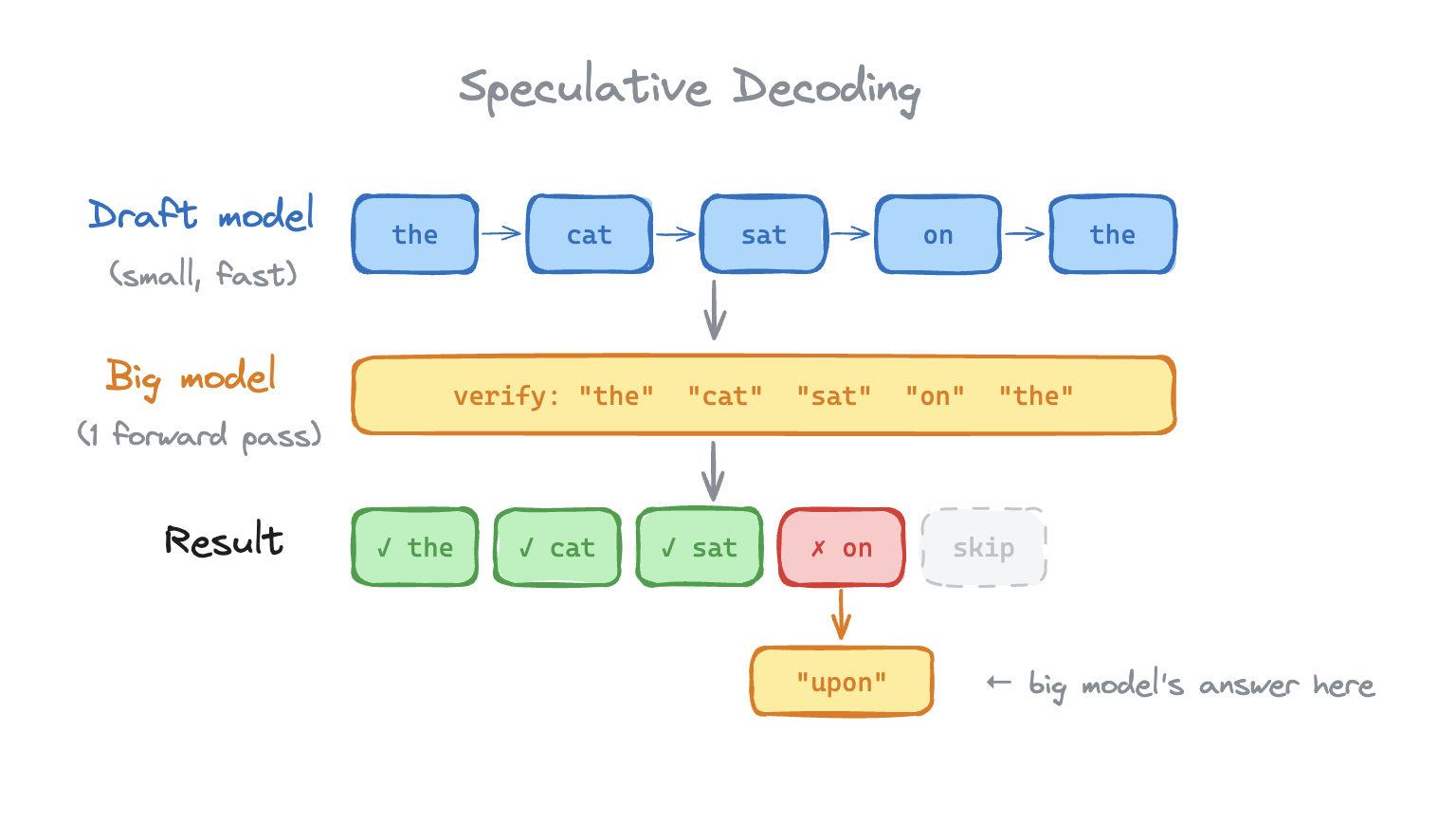
The goldilocks challenge here is the draft model size. Too dumb and most draft tokens get rejected and you waste compute. Too smart and you might as well just use the larger model directly.
Google uses Speculative Decoding in production for Gemini, the draft model is typically 10-20x smaller than the main model. They claim a 2-3x improvement in throughput!
Did you know your iphone also has speculative decoding built into it? Apple's on-device 3B parameter model uses it to make part of Siri run fast locally.
Paged attention
vLLM went from a Berkeley PhD project to the industry-wide serving stack in under a year because of paged attention.
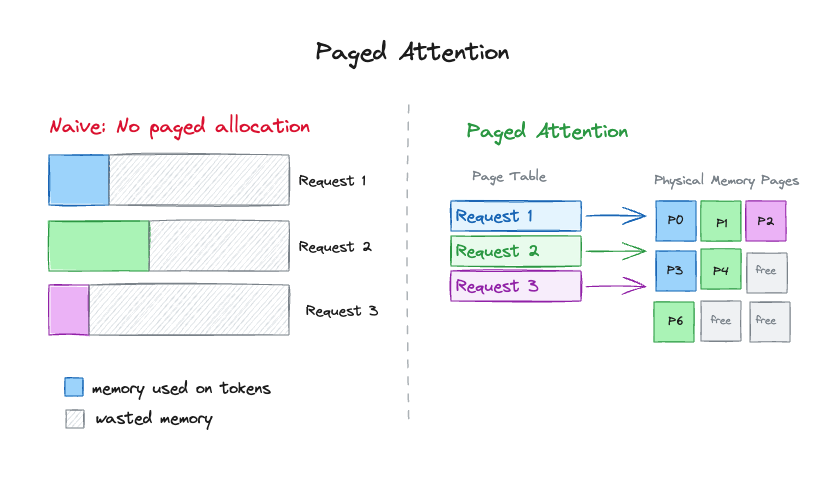
Traditionally, KV Cache for each request is allocated as one contiguous block the size of the entire context. Even if the user only uses a fraction of it. Solution?
Paged attention, much like virtual memory paging (did you pay attention in your OS class?), allocates KV cache in fixed-size blocks on demand. Thus, the KV Cache only consumes as much memory as it needs. Each block usually stores just 16-32 tokens, more requests can fit on the GPU simultaneously.
Quantization
Meta released the Llama 4 Maverick model that takes 1.6 TB at full precision. That would require 20 Nvidia H100s just to store the weights.
In practice, models are "quantized" to fit in the hardware. Instead of storing 32-bit floats, they're represented at lower precision.
This is the same trick video game developers have used for decades.
float bodyWeight = 67.5f; // who needs 32 bits to store a weight??
int8_t bodyWeight = 67; // less accurate but only takes 8 bits.
Just applying INT8 quantization with no other optimizations on the 1.6TB model reduces the size to ~400GB.
For model weights, INT8 is nearly lossless. INT4 is still used heavily for local inference but it comes with the quality tradeoff.
KV Cache Quantization
The inference frontier is still moving really fast. Google published TurboQuant (ICLR 2026), which quantizes the KV cache itself down to 3 bits. In practice, this would compress the KV Cache by ~5x over standard FP16.

Final thoughts
Next time ChatGPT streams a response to you, you'll know what's happening. Tokens. Attention. KV cache growing one row at a time. Speculative decoding, chunked prefill and other inference optimizations.

Appendix:
Tell me more!
We covered what happens between your prompt and the model's first token. But we skipped the last mile: how does the model actually pick that token? why does cranking up the temperature make it hallucinate? That's Part 3 of this series.
Show me the code!
If you want to peel back the layers yourself, you can start with WhiteLotus: an inference server that I wrote alongside this blog. Its bare bones so its very easy to tinker with and understand what a production level inference server like vLLM or llama.cpp is doing under the hood.